No-Hallucination AI Support Agent
A no-hallucination AI support agent grounds every answer in your documentation. The architecture, the guardrails, and the liability case for grounded support.
Article body
A no hallucination AI support agent is a support bot architected to refuse questions it cannot answer from your documentation, rather than guessing. The distinction matters more than most teams realize at evaluation time. A bot that invents a refund policy, a pricing tier, or a security claim is not a quirky AI behavior to be tolerated. It is a liability your team will own when a customer acts on the wrong information. The good news is that hallucination in support contexts is largely a solved problem at the architectural level. The bad news is that most vendors do not configure their defaults that way, and the difference is invisible until something breaks. This page covers what hallucination actually is, the architecture that prevents it, and the liability case for treating grounding as a non-negotiable feature.
What hallucination actually is
In machine learning terms, hallucination is when a language model produces output that is fluent and confident-sounding but factually wrong. The model is doing what it was trained to do: generate plausible-sounding text. The problem is that "plausible-sounding" and "true" are not the same thing, especially for facts the model has no real knowledge of.
In a support context, hallucination shows up in predictable patterns. The bot invents pricing tiers that do not exist. The bot describes features your product does not have. The bot quotes policies that sound reasonable but are not yours. The bot cites integrations, certifications, or support channels that you never set up. Each of these is a specific failure mode, and each one creates a specific customer expectation that you will then have to disappoint or expensively honor.
The reason this happens is that language models are trained on the public internet. They have seen thousands of SaaS pricing pages, refund policies, and feature lists. When asked about your specific product, the model fills in from this general background rather than admitting it does not know. The output reads as confident because the model is, statistically, drawing from real patterns in similar businesses. The fact that it is not drawing from your business specifically is invisible to the model and, often, to the visitor reading the answer.
Why generic AI hallucinates by default
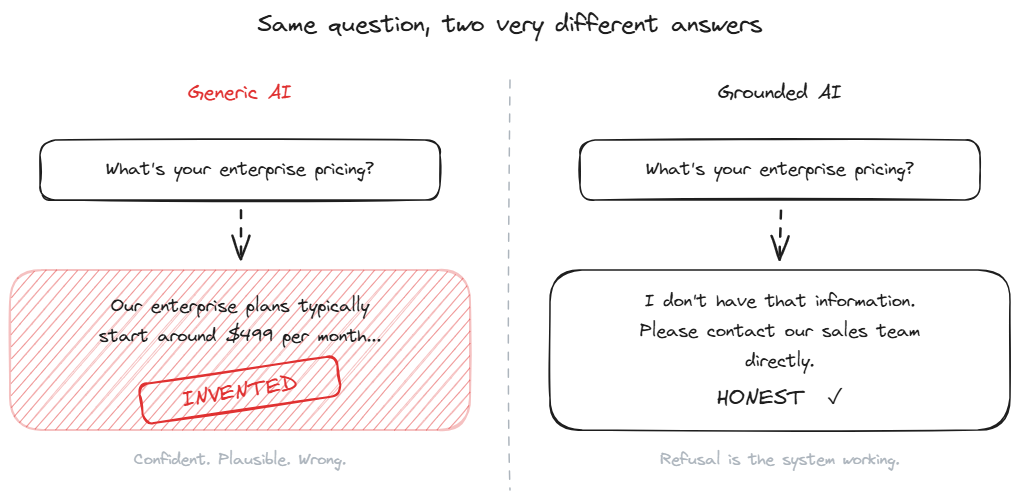
A general-purpose AI assistant (ChatGPT, Claude, Gemini accessed directly) hallucinates about your business by design, not by mistake. The model has no access to your private documentation. When asked a question it cannot ground, its options are to admit ignorance, to refuse, or to guess. Default settings on most consumer-facing AI tools favor producing an answer over refusing, because users perceive refusal as failure. The result is plausible guessing for any question that requires private knowledge.
A reliable support AI flips this default. Architecture, prompt design, and configuration combine to make the bot refuse rather than guess. The refusal looks like "I don't have that information" or "Please contact support@example.com directly." The refusal is not a bug; it is the system working correctly. A bot that refuses 15% of questions because they fall outside its knowledge base is operating well. A bot that answers 100% of questions, including the ones outside its knowledge base, is hallucinating on the 15% the first bot honestly refused.
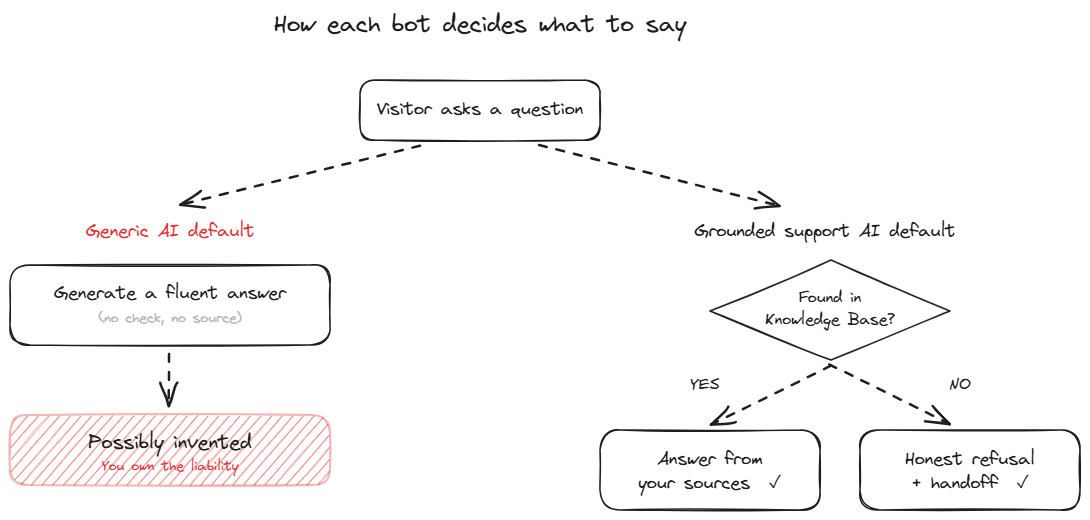
The architecture of a grounded chatbot
A grounded support bot has 3 layers working together to prevent hallucination.
The first layer is the retrieval system. Every question gets converted to an embedding and matched against the knowledge base. The system returns a relevance score along with the matched passages. If the top passages score below a threshold, the system flags the question as out of scope.
The second layer is the prompt. The model receives the retrieved passages and an explicit instruction along the lines of "answer only using the provided passages. If the passages do not contain the answer, respond that you don't have the information." This is the prompt-level guardrail. Done well, it constrains the model to the retrieved content. Done badly, it leaves the model free to fill in from its training data.
The third layer is the output filter. Before the answer reaches the visitor, the system can check whether the answer can be traced back to specific passages. Answers that cannot be traced (sentences the model generated without source backing) get flagged or rewritten. Some platforms simply discard such answers; others surface them to the visitor as "I don't have a confident answer for this."
The combination of these 3 layers reduces hallucination to a small fraction of what an ungrounded bot produces. The remaining hallucination risk comes from edge cases: passages that look relevant but are actually about a different topic, source content that itself contains errors, and questions phrased ambiguously enough that multiple passages match. Each of these has known mitigations, but none of them is fully eliminated.
Where hallucination still creeps in
Even with strong grounding, three patterns of hallucination remain.
The first is what researchers call "extractive distortion": the model retrieves the right passage but paraphrases it in a way that changes the meaning. The source says "refunds within 14 days," and the model outputs "refunds within about 2 weeks," which is close but not exact. For most casual questions this is fine. For legal, financial, or safety-sensitive contexts, exactness matters and paraphrase can drift.
The second is "stale source" hallucination. The bot retrieves a passage from a doc that is current in the knowledge base but out of date in reality. The source has not been updated yet. The bot answers correctly relative to the source, but wrongly relative to the world. This is a content management problem, not a bot problem, but it looks identical to a hallucination from the visitor's perspective. The cure is to keep the source current, often by correcting the entry yourself as soon as the real-world fact changes.
The third is "context conflation": the model retrieves passages from multiple documents and combines them in ways that create a meaning that neither document actually states. A passage about Plan A and a passage about Plan B get blended into a fictional Plan C with features pulled from both. Stronger systems include re-ranking and per-document attribution to reduce this; weaker systems just merge and hope.
Detection mechanisms for these residual cases include source-attribution logs, confidence-score thresholds, and human review of randomly sampled conversations. None of this fully eliminates hallucination, but all of it together reduces the rate to a level where the bot becomes safe to deploy on a public site.
The liability angle
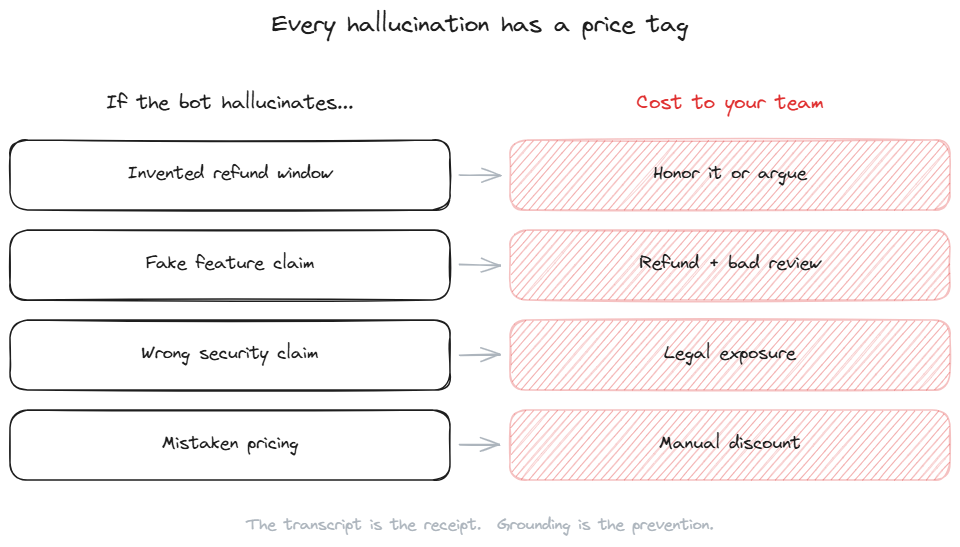
The most underrated reason to require grounding is the liability one. When a generic AI agent invents a feature your product does not have, you face a choice. Honor the made-up feature (expensive). Refuse to honor it (reputation damage). Argue with the customer about what the bot actually said (worst of both). Each path has a cost, and the customer has the conversation transcript to back their version.
In regulated industries the stakes are higher. A healthcare support bot that invents a drug interaction. A financial support bot that misstates a fee disclosure. A legal services bot that gives advice that turns out to be wrong. The cost of each individual hallucination is small. The cost of an aggregated pattern of hallucinations, documented in transcripts, is significant.
A grounded support agent reduces this risk substantially. Every answer is traceable to a source document. Every refusal is documented as a refusal, not a wrong answer. The audit log of bot responses becomes a defensible record rather than a liability. For teams evaluating support automation against a baseline of email or chat handled by humans, the liability comparison usually favors a well-configured grounded bot over an ungrounded one, even before any conversation about cost or speed. That defensible record is one piece of how a support bot earns trust.
BestChatBot's web widget architecture grounds every answer in your private knowledge base, with source attribution available for every response and a configurable refusal pattern for questions outside the knowledge base. The same architecture supports answer audit logs for teams that need to defend their bot's behavior after the fact.
For teams comparing options based on the hallucination-and-liability angle specifically, the Intercom alternative and Zendesk alternative pages cover how grounded support stacks up against incumbents in terms of both accuracy and the cost of getting it wrong.
FAQ
- Can hallucination be eliminated entirely? Not entirely, but it can be reduced to a small enough rate that the residual risk becomes manageable. The combination of strong retrieval, constrained prompts, output filtering, and a culture of honest refusal brings hallucination rates down significantly compared to ungrounded AI. The remaining cases mostly fall into the 3 categories described above and have known mitigations.
- How do I know if my current chatbot is hallucinating? Spot-check 50 to 100 random conversations from the past week and verify each bot answer against your actual documentation. Tag each as accurate, paraphrased-but-acceptable, distorted, or invented. Hallucination rates above a few percent indicate a configuration or architecture problem.
- Does grounding hurt the bot's conversational quality? Slightly, in the sense that a grounded bot refuses more questions and produces shorter, more focused answers. Most teams find this acceptable because the alternative (fluent answers that may be wrong) is worse for support contexts. For casual or open-ended conversational use cases, the trade-off may be different.
- What confidence threshold should I set for refusals? Higher thresholds mean more refusals and fewer wrong answers. Lower thresholds mean more guesses and more risk. A typical starting point is on the conservative side, and the threshold is tuned over time based on the rate of false negatives (refusals where the answer was actually in the docs) versus false positives (answers given when the docs did not actually contain the information). Note: this threshold is set by the vendor in many products and not always exposed to customers.
- What happens to the audit log if the bot hallucinates? A well-built system logs the retrieved passages used for each answer, so you can verify whether the answer traces back to real source content or was generated without source backing. Answers without source backing are the ones most likely to be hallucinations and the most useful to review.
A no hallucination AI support agent is the only kind that can be safely deployed at scale on public-facing surfaces in 2026. The architectural difference between a grounded bot and a generic one is large, the liability case is increasingly clear, and the cost of getting th
Related: for the brand and legal exposure of a bot that guesses, see hallucination liability and how grounding reduces it.
Grounding matters more in some fields than others. See how it plays out across a support agent tuned to each industry.
Grounded answers matter most where money is on the line. When customers ask billing/subscription policy questions, the agent must quote your real terms instead of inventing a refund window or renewal date.