AI Support That Learns From Feedback
AI support that learns from feedback turns live conversations into knowledge base improvements. See the 3 mechanisms and what makes the loop compound.
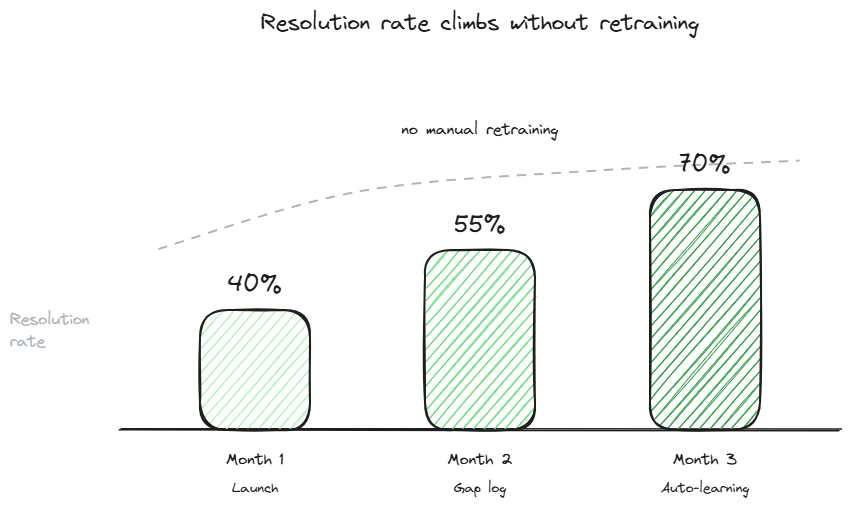
An AI support agent that learns from feedback is one that gets better at answering questions over time without anyone manually retraining it. The mechanism is straightforward in principle: capture the cases where the bot answered badly or could not answer at all, identify the gap in the knowledge base, fix the underlying content, and let the next visitor benefit. The result is a bot whose resolution rate climbs from launch baseline (typically 35-45%) to a mature level (70-80%) over a quarter or two, without a separate training project. This page covers the 3 mechanisms that make the feedback loop work, the patterns that break it, and what to measure to know whether your bot is actually learning or just running in place.
What "learning from feedback" actually means
The phrase covers something more specific than the marketing version suggests. A support chatbot does not "learn" in the sense of retraining its underlying language model. The model stays the same. What changes is the knowledge base the model retrieves from at the moment of each answer.
When the system captures a failure (a question the bot could not answer, or answered wrongly) and feeds the correct answer back into the knowledge base, the bot will answer correctly the next time a similar question comes in. The "learning" is mechanical: store the new content, re-index, serve. The intelligence sits in the capture mechanism and the validation step, not in the model.
This distinction matters because it changes what to invest in. Vendors emphasizing "our AI learns from every conversation" are often glossing over a manual process: someone reviews the logs, decides which exchanges are useful, and adds the content to the KB. Vendors with genuine automated feedback loops have a system that does this capture and validation without human review for the cases where it can, and flags the ambiguous cases for human attention. The second kind of system scales; the first does not.
The 3 mechanisms that turn conversations into knowledge
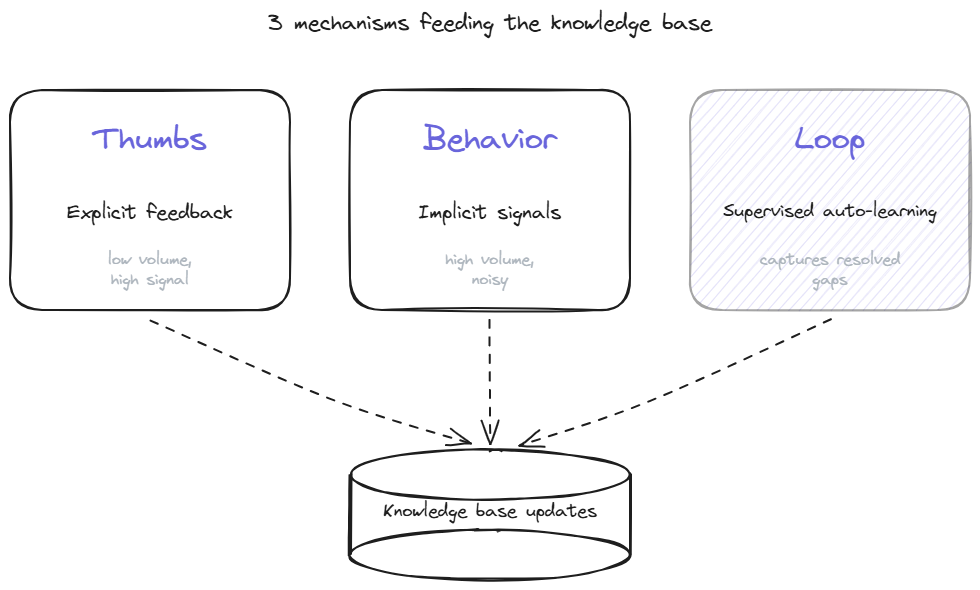
A support AI improvement loop pulls from 3 distinct signal sources, each with different volume and reliability characteristics.
The first is explicit feedback. Thumbs up and thumbs down buttons under each bot response. A small percentage of visitors actually click them, but the ones who do are leaving a clean signal: the bot was helpful or it was not. Explicit feedback is low-volume and high-signal. It works well for catching the worst answers (the visitor who hits thumbs-down is rarely wrong about the answer being bad) and not for catching the merely mediocre ones.
The second is implicit feedback from behavioral signals. Did the visitor follow up with a clarifying question? Did they close the chat without responding? Did they then contact support through a different channel within the next 24 hours? These signals are high-volume and noisy. A visitor who closes the chat might have been fully satisfied or fully frustrated; the signal alone cannot distinguish. Useful in aggregate, hard to use case by case.
The third is the supervised autolearning loop, which captures cases where the bot said "I don't know" and a human then answered the same question through email, ticket, or another support channel. The system pairs the unanswered question with the human resolution, runs the pair through a validation pipeline (relevance, novelty, quality, on-topic vs off-topic), and adds the validated answer to the knowledge base. This is the highest-leverage of the 3 mechanisms because every captured pair represents a real gap in coverage that has now been closed.
Where the feedback loop actually compounds
Not every conversation produces useful feedback. Most successful conversations produce nothing actionable, because the bot answered correctly and there is nothing to learn. The compounding happens specifically on the edges: questions the bot did not know, questions where the visitor was unsatisfied, and questions where multiple visitors are asking the same thing in ways the current docs do not cover.
The first month after launch produces the most learning per conversation because the gaps are obvious and there are many of them. A typical knowledge base at launch covers 40-50% of incoming questions well. The first 20 to 30 captured failures usually point to a small number of broad gaps: a missing FAQ on billing, an outdated section on the integrations page, a doc that was written for engineers but is being asked about by end users. Fix these and the resolution rate jumps significantly in week 2 or 3.
By month 3, the easy gaps are closed and the learning curve flattens. The remaining failures are edge cases, ambiguous phrasings, and questions where the underlying business policy itself is unclear (so the bot cannot give a clean answer because there isn't one). The conversation learning at this stage requires more judgment per case but yields smaller individual improvements. This is the point where most teams either keep investing 30 minutes a week and continue improving, or stop investing and watch resolution rate plateau permanently.
The compounding effect is what makes feedback-driven AI worth the architectural investment over a static bot. A bot that does not learn stays at its launch baseline forever. A bot that learns can climb 25-35 percentage points over a quarter, which translates directly to fewer tickets reaching the human support team.
What to measure to know the loop is working
Three metrics tell you whether the feedback loop is producing actual continuous improvement or just generating activity.
Resolution rate over time, tracked weekly. The number to watch is the trend, not the absolute value. A bot that starts at 40% and reaches 60% by month 3 is learning. A bot that starts at 40% and stays at 40% is not, regardless of how much "feedback" the system claims to be processing.
Gap closure rate. Of the questions the bot could not answer last week, how many can it answer this week? A healthy loop closes 50-70% of last week's gaps within 7-10 days. A broken loop closes under 20% because the captured gaps never make it back into the knowledge base.
Time from gap to fix. The median number of days between a question being asked unsuccessfully and the bot being able to answer that question. Best-in-class is under 7 days. Above 30 days means the loop is slow enough that customers are asking the same questions multiple times before the answer appears.
BestChatBot's web widget includes all 3 mechanisms (explicit feedback, implicit signal tracking, and the supervised autolearning loop) as standard, and surfaces these 3 metrics in the admin dashboard so the team can see the loop's health without building separate reporting.
For the testing side that goes alongside this (verifying that the new knowledge actually fixed what it was supposed to fix), the evaluate outputs page covers the QA methodology.
Common mistakes that break the loop
Three failure modes show up across teams that have a feedback mechanism but no actual improvement to show for it.
The first is capturing without validating. Some systems automatically add every "human resolution" back to the knowledge base without checking whether the resolution was actually correct, on-topic, or worth keeping. The KB fills up with noise, contradictions, and casual chat that was never meant to be authoritative content. The bot's answers get worse, not better, because retrieval starts surfacing the noise.
The second is validating but not acting. The system flags gaps and surfaces them in a dashboard, but nobody on the team actually reviews the dashboard or makes the content changes. The bot's coverage stays flat because the loop is broken between capture and update.
The third is acting on the wrong signal. Teams that focus only on explicit feedback (thumbs up/down) miss the much larger volume of implicit signals and autolearning opportunities. Explicit feedback captures less than 5% of bot interactions. The other 95% contain useful information that requires the other 2 mechanisms to extract.
The fix for all 3 is the same. Run the loop on a weekly cadence with explicit ownership. Someone reviews the gap log, validates or rejects captured pairs, and updates the source content. 30 minutes a week is enough for most products. Without that 30 minutes, the architecture cannot save you. When a gap needs a precise correction rather than a re-crawl, that is manual knowledge editing.
FAQ
- Does the bot's underlying model actually learn, or just the knowledge base? The knowledge base, not the model. The language model stays the same. What changes is the content the model retrieves from at the moment of each answer. The practical effect is similar (the bot answers more questions correctly over time), but the mechanism is faster and more controllable than model retraining.
- How much human review does the feedback loop need? The autolearning side runs largely without human review for clear-cut cases (questions with unambiguous answers in the human-provided resolution). Ambiguous cases get flagged for human review. The typical time commitment is 30 minutes per week for a team handling a few thousand bot interactions; less for smaller volumes.
- What happens to bad feedback? A visitor who clicks thumbs-down on a correct answer (it happens) does not automatically degrade the knowledge base. The validation step requires more than one signal to act on a piece of feedback, and explicit feedback alone does not modify the KB. The autolearning loop validates against multiple criteria before adding content.
- Can the bot learn from feedback in multiple languages? Yes. The capture and validation work language-by-language for the questions, and the knowledge base updates apply across all retrieval languages because the underlying embeddings are multilingual.
- How quickly do new knowledge base entries become live? Manual additions are usually live within minutes. Autolearning-added entries go through validation first and typically appear within 24 to 48 hours of the original capture.
For pricing details on plans that include the full feedback loop, see pricing. To estimate what improvement to your resolution rate is worth, the improvement ROI tool gives a starting framework.