Knowledge Base Chatbot
A knowledge base chatbot answers from your own docs and FAQs, not from generic AI. See how grounded retrieval works and how to set it up on any site.

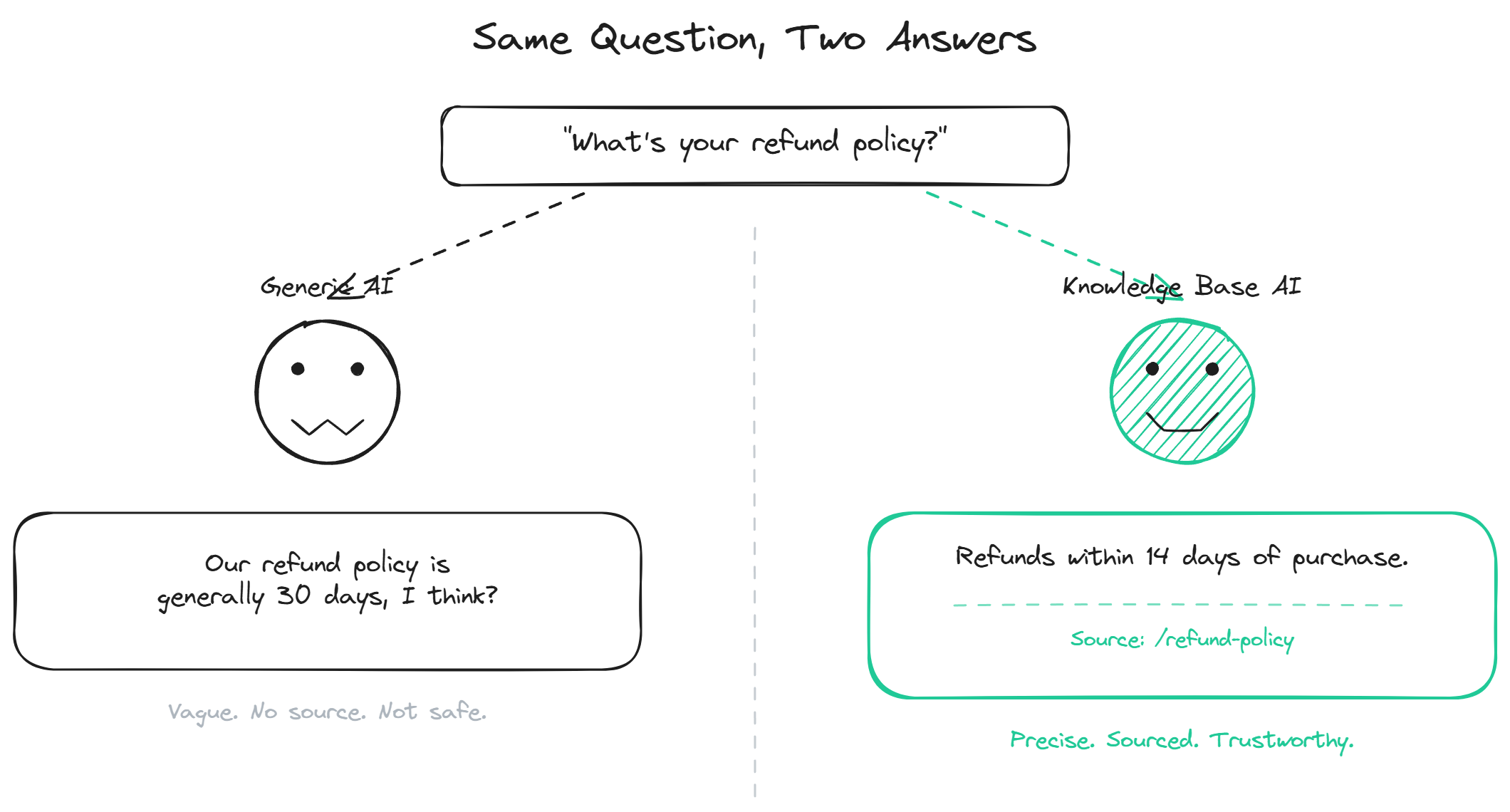
A knowledge base chatbot is a chatbot whose answers come from your own documentation rather than from a language model's general training data. The distinction sounds technical but it determines almost everything about how the bot behaves on a live website. A grounded bot quotes your docs, sticks to your policies, and refuses to answer questions it cannot back up. A non-grounded bot improvises, sounds confident, and contradicts your help center within the first 5 conversations. This page covers what a knowledge base chatbot actually is, the architecture that makes it accurate, and what teams should do before installing one on their site.
What a knowledge base chatbot actually is
In technical terms, a knowledge base chatbot is a chatbot built on retrieval-augmented generation. The language model itself is not trained on your content. Instead, the bot keeps your documentation in a searchable knowledge base, retrieves the most relevant passages when a visitor asks a question, and hands those passages to the model along with the question. The model writes the answer using the retrieved content as its source, not its own training data.
The practical effect of this architecture is that the bot's answers are constrained to information you control. Add a document, and the bot can answer from it minutes later. Remove or update a document, and the bot's answers shift accordingly. There is no retraining cycle, no model fine-tuning, no waiting weeks for the bot to learn new content. The knowledge base is the bot's memory, and it updates as fast as you can edit the underlying sources.
This is the architecture behind every credible support chatbot in 2026. Vendors that still pitch their product as "fine-tuned on your data" are usually overselling something simpler. The retrieval-augmented approach is what makes a grounded support AI possible at the price points that work for SaaS support.
Why grounding in your content beats general-purpose AI
A general-purpose AI assistant (ChatGPT, Claude, Gemini) is trained on the public internet up to some cutoff date. Ask it about your product and it will either say it does not know, or it will guess based on whatever it absorbed about similar products. Both outcomes are bad on a live support page. The "I do not know" answers waste the visitor's time. The guesses can be confidently wrong about your pricing, your features, or your policies.
A knowledge base chatbot fills exactly this gap. Visitors get answers that reflect your current docs, not a model's stale general understanding. The bot quotes your pricing page accurately, not a competitor's price from 2023. The bot follows your refund policy, not a generic industry average.
The other thing grounding does is reduce hallucination. A model constrained to retrieved passages cannot easily invent a feature that does not exist or quote a policy that is not yours. The grounded AI page covers the hallucination reduction side in detail. The short version is that the constraint comes from the prompt, not from any property of the model itself, and the quality of the constraint depends on the quality of the retrieval. That restraint is part of the trust controls behind the bot.
What goes into a useful knowledge base
The knowledge base is the substance of the bot. What you feed in determines what comes out. Most modern systems accept 4 types of source content.
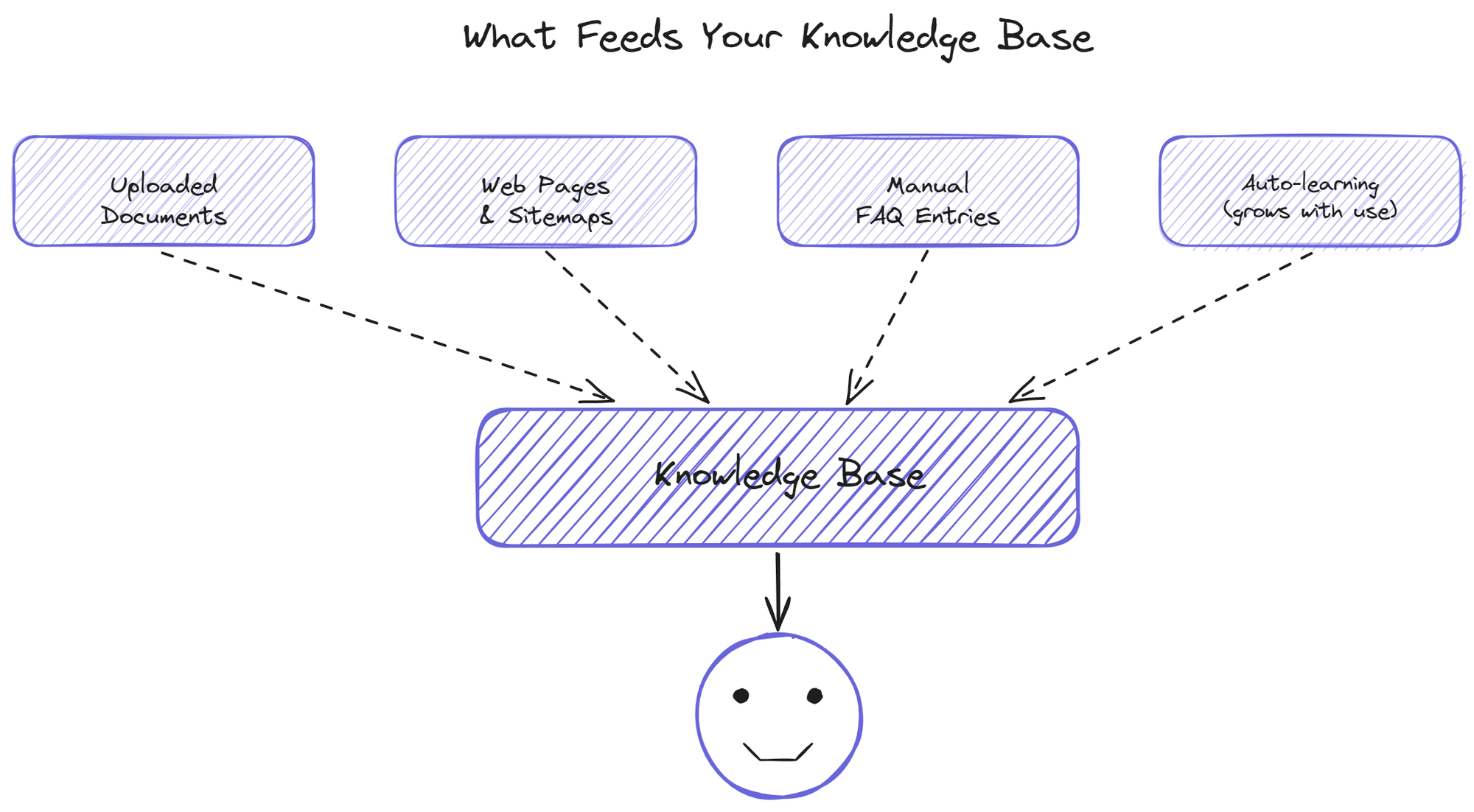
Uploaded documents are the most common source. PDFs of product manuals, internal FAQ exports, whitepapers, policy documents. The bot reads the text, splits it into passages, and indexes them for retrieval. This works well for stable content that does not change weekly.
Web scraping covers content that already lives on a public page. Point the bot at a URL or a sitemap, and it pulls the content from those pages on a schedule. Help center articles, public documentation sites, FAQ pages. The advantage is that the bot stays in sync with what visitors see on the public site without manual re-uploads.
Manual FAQ entries cover the questions that do not have a doc yet. Type the question and the answer into the admin panel, and the bot has it. Useful for product-specific edge cases, recently launched features, or anything that has not made it into the formal docs yet. You can also write and revise answers directly whenever an existing reply needs a correction.
The fourth type is the autolearning input: questions the bot could not answer and that were resolved through other channels. Some platforms (including BestChatBot) capture these and add them to the knowledge base after a validation pass that checks relevance and quality. This is the source category that grows automatically with use.
For the deeper version of how source selection and content prep work, the set knowledge page covers the full training process.
How the bot answers: retrieval and generation
The pipeline a knowledge base chatbot runs on every question follows a consistent pattern across vendors. Understanding it helps with both evaluation and debugging.
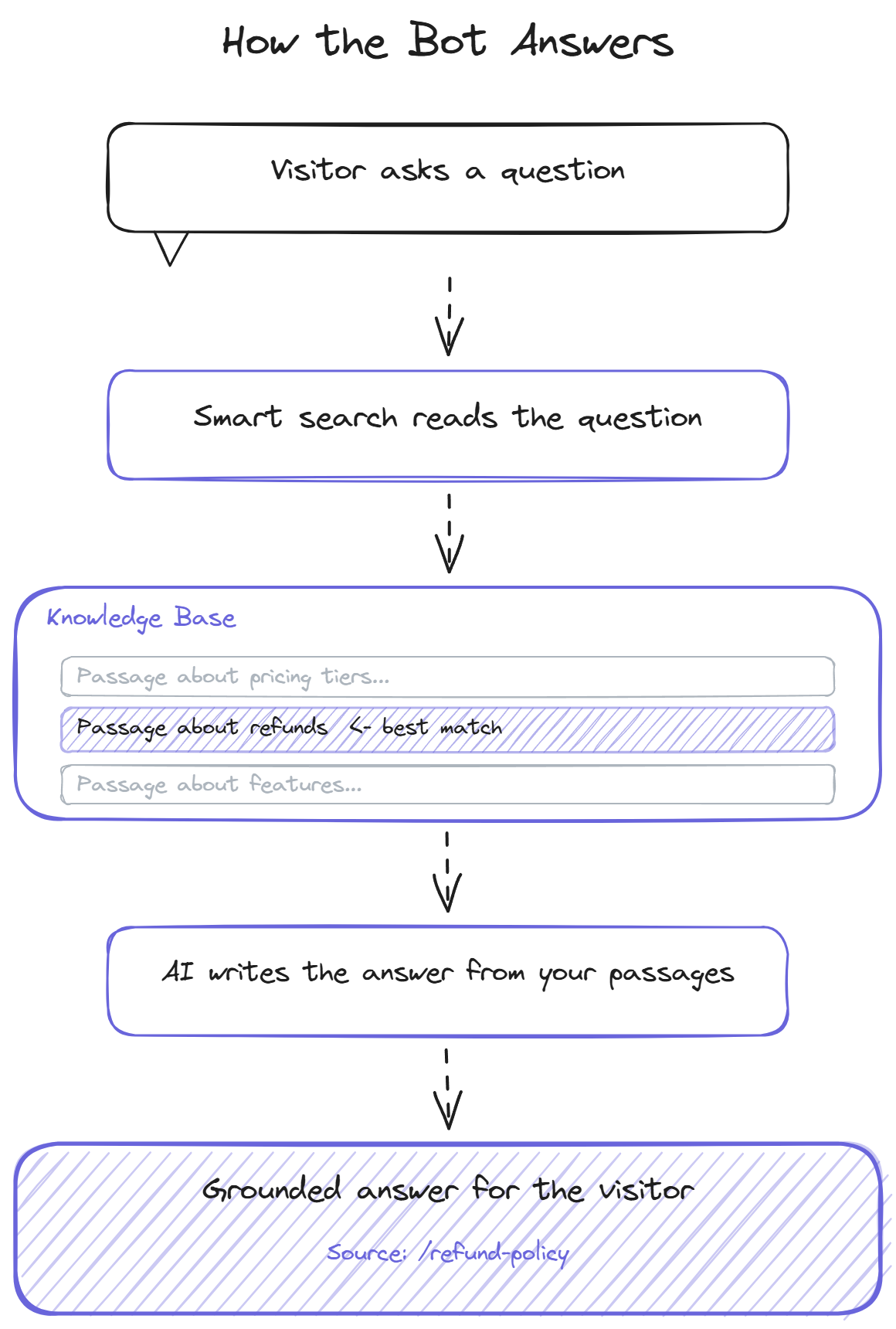
The question gets converted into a vector embedding, which is a numerical representation of its meaning. The knowledge base also stores embeddings for every passage in the indexed content. The retrieval step finds the passages whose embeddings are closest to the question's embedding, which surfaces the content most semantically related to what the visitor asked.
The retrieved passages and the original question get passed to the language model with a prompt that constrains the model to answer using the passages. The model generates a response in natural language, paraphrasing or quoting the source content. A well-built system attaches the source references to the answer so the visitor can verify or dig deeper.
BestChatBot adds a knowledge graph layer on top of the vector search, which tracks entities (products, features, plans, error codes) and their relationships across passages. This sharpens retrieval for questions that mix multiple concepts, where pure similarity search alone tends to surface partially-relevant passages.
Where teams trip up on knowledge base setup
The 3 most common failures all happen before the bot is even installed.
- The first is feeding the bot internal content not written for end users. Slack threads, engineering design docs, internal wikis. The bot will dutifully quote whatever it indexes, including jargon and context that confuses public visitors. Source content should be readable by the people who will receive the answers.
- The second is treating the knowledge base as a one-time upload. Documentation changes weekly in active products. Pricing tiers shift, features ship, policies get updated. A knowledge base that was current in January and never refreshed produces January answers in November. Most platforms support scheduled re-indexing; configure it on day one.
- The third is skipping the content audit. Existing help centers usually have duplicates, outdated articles, and pages that contradict each other. The bot will retrieve whichever passage scores higher, which means the same question gets different answers on different visits. The audit is unglamorous but it determines whether the bot is consistent.
FAQ
- Is a knowledge base chatbot the same as a chatbot trained on docs? The terms are used interchangeably in vendor marketing. Both refer to the retrieval-augmented architecture described above. The bot is not literally trained on the docs in the machine-learning sense; the docs sit in a retrieval system and feed into each answer.
- How much content does the knowledge base need? Enough to cover the top 30 to 50 most common visitor questions. For most SaaS products, this is a help center of 30 to 80 articles plus a few PDFs. Volume past that point matters less than coverage of the actual question distribution.
- Can the bot answer questions outside the knowledge base? A well-configured bot says "I do not have that information" when the retrieval does not surface relevant content. A poorly configured bot falls back to the model's general knowledge, which is where hallucination starts. The behavior is a configuration choice; verify which mode any vendor's default uses.
- How fast does the knowledge base update? For manual uploads or FAQ edits, the update is usually live within minutes. For scraped URLs, it depends on the refresh schedule (daily and weekly are common). Some platforms also support manual re-indexing for urgent changes.
- Does the knowledge base work across multiple languages? Modern systems use multilingual embedding models, which means a question in Spanish can match a passage in English and the bot can generate the answer in Spanish. You maintain the knowledge base in one language and the bot handles the cross-language matching automatically.
A knowledge base chatbot is the foundation of every credible AI support tool in 2026. The architecture is mature, the constraints are well-understood, and the difference in answer quality between a grounded bot and a generic one is large enough to be obvious from the first conversation. To see pricing and pick a plan, head to pricing.
For more setup help, browse our support guides and resources.
Documentation-heavy products have their own support shape. See the AI support agent for SaaS.